当我有一个想法,使用Spring Data Redis的时候,我想到了JPA, 想到了Spring Data Mongo,一想Spring Data统一了Dao层的编程模型,我就觉得我可以轻松驾驭Spring Data Redis,果然想法是天真的。当我准备启动项目的时候,就报了一个错误:
*************************** APPLICATION FAILED TO START *************************** Description: A component required a bean of type 'com.example.demo.repository.VocabularyEntityRepository' that could not be found.
然而我明明看到了

我也是加了@Repository注解,同时也看到了Bean的图标,但是确告诉我没有注入这样的Bean,就很疑惑,同样我也没有办法直接判断为什么没有注入成功。一想到以前没有注入成功的原因大半是因为package的问题导致没有扫描到,现在我再三检查了一下,也没有问题。第二就是我想到是不是命名的问题导致的,几经折磨,发现并不是。
这时时间已经过去了许久。我想这时候就开始看官网了,首先是找到Spring Data Redis 的文档看了一番,然而并没有看到什么问题,一想到Spring Data Redis肯定是开箱即用的,也就是我不需要额外的配置,除非我使用的不是默认的配置,显然我是完全按照默认的配置来的,所以我排除了配置的原因。
接着,我想到了Spring Data Example这个项目,这是一个示例项目,也就是怎么使用的问题。果然,还是这个好使。一会我就找到了答案:
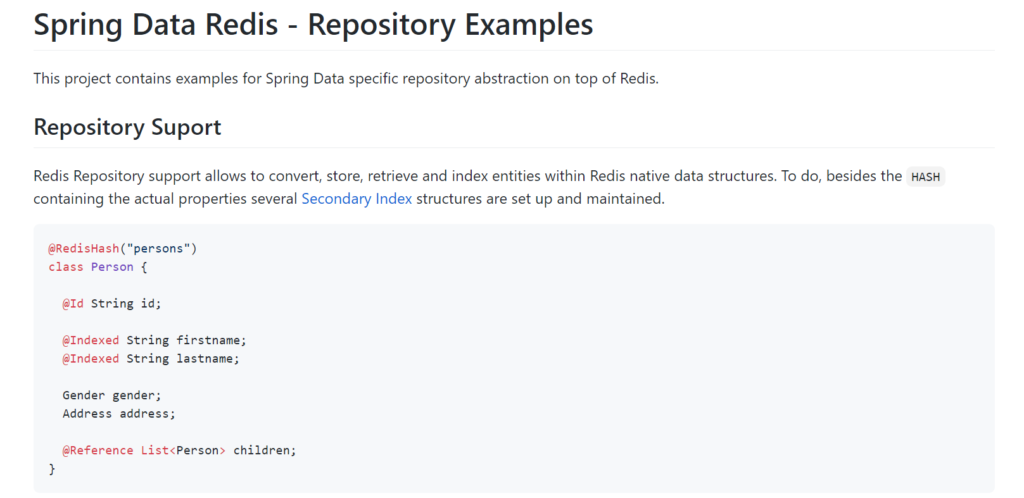
原来我少的一个关键的注解,那便是@RedisHash(“xxx”), 这一下就让我想起了以前用关系型数据库mysql,postgresql,时,我会在实体上标注@Entity,使用mongo或者es的时候,我会用@Document。
当然,我第一次还看到了下面的配置:
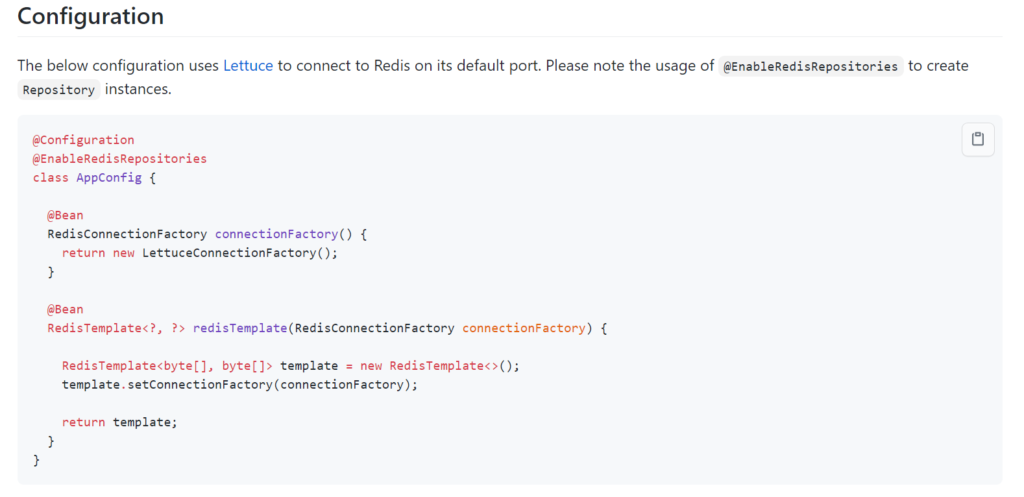
一看到@EnableRedisRepositories再结合错误,没有找到Repository,自然一下子就看到了曙光,一顿操作,果然服务起来了。
然后,我理解Spring Data Redis也应该是默认就开启了@EnableRedisRepositories,所以我尝试删除了这个配置类也是可以启动了,验证了我的想法。
最后,我想这次解决没有找到Repository的问题,其实是个人经验总结和摸索出来的,但是我看到了一个更好的解决问题的模型——那便除了文档之外,我们可以直接看别人的示例源码,因为在我们用之前,它肯定提供了示例。
当然,我在看到官方提供的示例源码之前,也看到了一些别人写的代码,但是,就算源码中包含了解决方案,也会被更多的变量所覆盖,比如版本问题,以及版本带来的依赖问题,Api变化问题,等等,所以一下子很难看到是哪个原因导致的。所以在分析原因的时候,我们要控制好变量。不然,很容易就被带歪了,比如,我看到了一个示例代码就有:
但是,我那时并没有关注到这个注解@RedisHash(“xxx”)。
敏锐的目光需要不断地打磨,因为你要知道Repository的原理的话,估计就不会出现这些问题。但是平时大都在应用层,我们更多的关注点都在使用Api,并没有深层次的了解那些看起来不起眼的注解上,比如在Feign API时,就经常出现项目没有办法启动,因为就是少了注解,比如@RequestParam.
记在最后,当使用的示例是最好的学习方式,应该这样能最快地解决应用问题。
原本,文章到此就结束了,但是我想起来今天看文档地一点收获也顺便记一下。
我发现Redis也是可以支持Geo的,这让我联想起了Mongo也是支持同样的操作的,然后就顺便看了一下例子:
@RedisHash("people")
public class Person {
@Id String id;
@Indexed String firstname;
String lastname;
Address hometown;
}
public class Address {
@GeoIndexed Point location;
}
再看@GeoIndexed注解就很亲切。
Find using Geo Index:
repository.findByHometownLocationNear(new Point(15, 37), new Distance(200, KILOMETERS));
List findByAddressLocationWithin(Circle circle)
这行代码看上去就很美,此时的心情也很美。


